The open source tools are free to use and it allows people to modify the source code. Some of the open source tools for data annotation are: CVAT, LabelImg, Doccano, VoTT.
Commercial tools
Using this type of tool will require payment, however, it allows users to customize the functions to suit their need. The best commercial tools can be named: LinkedAI, Dataloop AI, Tagtog, LightTag.
Freeware tools
Similar to open source tools, freeware tools do not charge any fees. You can download and use freeware but cannot modify them. An example of this type of tool is Colabeler, SuperAnnotate
You can walk through our video guidance series about AI Data Labeling Tools if you still wonder how to choose the best tools for your data labeling project.
Without a Data Annotation Tool, the AI Data Processing is impossible. Some might choose the open source tool, some might come for the vendor source tool or even develop their own tool. With either of these, it is essential for businesses to consider top 5 annotation tool features to find the most suitable one for their products:
Dataset management
Annotation Methods
Data Quality Control
Workforce Management
Security
What’s a data annotation tool?
A data annotation tool is a cloud-based, on-premise, or containerized software solution that can be used to annotate production-grade training data for machine learning. Cloud-based data annotation tool (SaaS) is a tool built on top of a cloud platform. With objects being stored in the cloud, training data is reliably secured. A team can easily simultaneously annotate multiple datasets in real-time without any glitches. On-Premise data annotation tool is a tool used within the premise of a business. On-Premise tools are favoured due to the data security and the quick response whenever issues occur. This kind of tool often requires licenses to use and higher costs for maintenance and management.
Common AI data processed include image annotation, video annotation, voice annotation, and text data annotation. You can either buy/lease a data annotation tool or build it yourself. It depends on how you want to manage your datasets and your requirements regarding security and frequency of customization. No matter what approach you choose, you always have to go through the phase of analyzing your projects.
These are some requirements you need to clarify before going into any AI Data Processing project:
You want to begin a machine learning project. You already have the data you want to clean and annotate to train, test, and validate your model.
You have to work with a new data type and need to understand the best tools available for annotating that data.
In the production stage, it is a must to verify models using human-in-the-loop.
After clarifying these three requirements for your annotation process, businesses can easily identify which annotation tool is the best for their firm by going through five features of any annotation tool.
Annotation Tools play a vital role in the success of the whole annotation process. They not only help boost up the speed and output quality, but also assist businesses in management and security. By the way, the features below may also help you to understand the whole process if you are interested in a job as a data specialist.
1. Dataset management
Annotation begins and ends with a comprehensive way of managing the dataset you plan to annotate, which is a critical part of your workflow.
Therefore, you need to ensure that the tool you are considering will actually import and support the high volume of data and file types you need to label. This includes searching, filtering, sorting, cloning, and merging of datasets.
Different tools can save the output of annotations in different ways, so you’ll need to make sure the tool will meet your team’s output requirements.
Your annotated data must be stored somewhere, so it is necessary for one to confirm support-file storage targets.
Another thing to consider when forming dataset management is the share and connect ability of the tool. Annotation specifically and AI data processing generally are sometimes done with offshore agencies, therefore the need for quick access and connectivity to the datasets.
2. Annotation methods
This is considered the core feature of data annotation tools – the methods and capabilities to apply labels to your data.
Depending on your current and anticipated future needs, you may wish to focus on specialists or go with a more general platform.
The common types of annotation capabilities provided by data annotation tools include building and managing ontologies or guidelines, such as label maps, classes, attributes, and specific annotation types.
Moreover, an emerging feature in many data annotation tools is automation, or auto-labeling. Using AI, many tools will assist your annotators to improve their skills in labeling data or even automatically annotating your data without a human touch.
Some tools can learn from the actions taken by your human annotators to improve auto-labeling accuracy.
If you use pre-annotation to tag images, a team of data labellers can determine whether to resize or delete a bounding box. This can shave time off the process for a team that needs.
Still, there will always be exceptions, edge cases, and errors with automated annotations, so it is critical to include a human-in-the-loop approach for both quality control and exception handling.
3. Data quality control
The performance of your machine learning and AI models will only be as good as your data, whereas Data annotation tools can help manage the quality control (QC) and verification process. Ideally, the tool will have embedded QC within the annotation process itself.
For example, real-time feedback and initiating issue tracking during annotation are important. Additionally, these can support workflow processes such as labeling consensus. Many tools will provide a quality dashboard to help managers view and track quality issues, and assign QC tasks back out to the core annotation team or to a specialized QC team.
4. Workforce management
Every data annotation tool is meant to be used by a human workforce, even those tools that may lead with an AI-based automation feature. You still need humans to handle exceptions and quality assurance as noted before.
Hence, leading tools will offer workforce management capabilities such as task assignment and productivity analytics measuring time spent on each task or sub-task.
5. Security
Whether annotating sensitive protected personal information (PPI) or your own valuable intellectual property (IP), you want to make sure that your data remains secure.
Tools should limit an annotator’s viewing rights to data not assigned to her, and prevent data downloads. Depending on how the tool is deployed, via cloud or on-premise, a data annotation tool may offer secure file access (e.g., VPN).
Choosing an annotation tool is seemingly an easy task, perhaps because there are plenty of choices on the market.
However, no matter how many annotation tools there are to offer, your businesses are still under the risk of choosing the unsuitable one. To prevent this, you need to know the fundamentals of how to choose the right annotation tool, and necessary data annotation tool features to be put into consideration are security, HR management, data quality control, annotation methods, and dataset management.
Too busy to list these features out? Get consults from LQA to come up with data annotation services for your business. Contact us now for full support from experts.
This is the first video of the series 5 Essentials of AI Training Data Labeling work. Ngoc will talk about data quality and its determinants.
You can watch our video here, or read the transcription below. Turn on subtitles for English, Japanese, Korean and Vietnamese
Hello everyone, my name is Bich Ngoc from Sales Department of Lotus Quality Assurance. You can also call me Hachi.
Welcome to LQA channel. Our channel is aimed at sharing information about testing and data annotation for AI development. If you want to see more helpful videos from our channel, please like and subcribe to our channel.
You are…
Dealing with massive amounts of data you want to use for machine learning?
Doing most of the work in-house but now you want your team to focus on more strategic initiative?
Thinking about outsourcing the data annotation work but still have a lot of concerns?
These video series are totally for you.
With 5 videos in the series, we will take you through the essential elements of successfully outsourcing this vital but time consuming work.
Our sharing is not only from the perspective of a data labelling service provider but also a quality assurance company. So I hope you guys will find it fresh and helpful.
Data Quality
Scale – What happens when my data labeling volume increases
Tools – Do I need a tooling platform for data labeling
Cost
Security – How will my data be protected
Today I will introduce you to one aspect you have to consider when you prepare a data set for your AI: DATA QUALITY.
What is Data Quality?
First of all, let’s get to know what Data Quality is.
Simply put, data quality is an assessment whether the given data is fit for purpose.
Why is there even a question of quality when it comes to data for AI?
Isn’t having access to huge amounts of data enough?
The answer is no.
Not every kind of data, and not every data source, is useful or of sufficiently high quality for the machine learning algorithms that power artificial intelligence development – no matter the ultimate purpose of that AI application.
To be more specific, the quality of data is determined by accuracy, consistency, completeness, timeliness and integrity.
Accuracy: It measures how reliable a dataset is by comparing it against a known, trustworthy reference data set.
Consistency: Data is consistent when the same data located in different storage areas can be considered equivalent.
Completeness: the data should not have missing values or miss data records.
Timeliness: the data should be up to date.
Integrity: High-integrity data conforms to the syntax (format, type, range) of its definition provided by e.g. a data model
Why is data quality important?
For example, if you train a computer vision system for autonomous vehicles with images of mislabelled road lane lines, the results could be disastrous.
In order to develop accurate algorithms, you will need high-quality training data labelled by skilled annotators.
3 Workforce Traits that Affect Quality in Data Labelling
In our years of experience providing managed data labelling teams for start-up to enterprise companies, we’ve learned three workforce traits affect data labelling quality for machine learning projects: knowledge and context, agility and communication.
Knowledge and context
Firstly, for highest quality data, labelers should know key details about the industry you serve and how their work relates to the problem you are solving.
For example, people labeling tomato images will pay more attention to the size, color and the condition of each tomato if they know the data they are labeling will be used to develop AI system supporting tomato harvest.
Agility
Secondly, your data labeling team should have the flexibility to incorporate changes that adjust to your end users’ needs, changes in your product, or the addition of new products.
A flexible data labeling team can react to changes in data volume, task complexity, and task duration.
Communication
Last but not least, you need data labelers to respond quickly and make changes in your workflow, based on what you’re learning in the model testing and validation phase.
To do that kind of agile work, you need direct communication with your labeling team.
To conclude, high-quality training data is necessary for a successful AI initiative.
Before you begin to launch your AI initiative, pay attention to your data quality and develop data quality assurance practices to realize the best return on your investment.
You can watch our next video on Scaling Data Annotation, or other videos in the series.
Data is the foundation of all the AI projects and there are different ways to prepare datasets, including collecting through the internet or consulting an agency. So, what is the best way to get raw data for the AI Data Training process?
One suggested way to collect the train and test data is to visit various open labeled resources like Google’s Open Images and mldata.org or many other websites providing datasets for training in ML projects. These platforms supply you with an endless multitude of data (mostly in the form of images) to start your training process.
Depending on what kind of datasets you’re looking for, you can divide it into these categories of:
Open Dataset Aggregators
Public government Datasets for machine learning
Machine Learning Datasets for finance & economics
Image datasets for computer vision
For a high-quality machine learning / artificial intelligence project, datasets for training is the top priority that defines the outcome of the project. For the qualified and suitable datasets, you can consider the following filters to find the most suitable ones.
Open Dataset Aggregators
The most common thing that you might be looking for when working on machine learning / artificial intelligence is a source of free datasets. Open dataset finders that you can use to browse through a wide variety of niche-specific datasets for your data science projects. You can find it in:
1. Kaggle: A data science community with tools and resources which include externally contributed machine learning datasets of all kinds. From health, through sports, food, travel, education, and more, Kaggle is one of the best places to look for quality training data.
2. Google Dataset Search: A search engine from Google that helps researchers locate freely available online data. It works similarly to Google Scholar, and it contains over 25 million datasets. You can find here economic and financial data, as well as datasets uploaded by organizations like WHO, Statista, or Harvard.
3. OpenML: An online machine learning platform for sharing and organizing data with more than 21.000 datasets. It’s regularly updated and it automatically versions and analyses each dataset and annotates it with rich meta-data to streamline analysis.
Public government Datasets
For machine learning projects concerning social matters, public government datasets are very important. You can find useful datasets in these following sources:
4. EU Open Data Portal: The point of access to public data published by the EU institutions, agencies, and other entities. It contains data related to economics, agriculture, education, employment, climate, finance, science, etc.
5. World Bank: The open data from the World Bank that you can access without registration. It contains data concerning population demographics, macroeconomic data, and key indicators for development. A great source of data to perform data analysis at a large scale.
Machine Learning Datasets for finance & economics
The use of machine learning / artificial intelligence for finance & economics has long been very promising with the vast implementation in algorithmic trading, stock market predictions, portfolio management, and fraud detection. The quantity for this is very big thanks to the datasets built over many years. You can find the easily accessible datasets for finance & economics here:
6. Global Financial Development (GFD): An extensive dataset of financial system characteristics for 214 economies around the world. It contains annual data which has been collected since 1960.
7. IMF Data: International Monetary Fund publishes data related to the IMF lending, exchange rates, and other economic and financial indicators.
Image datasets for computer vision
Medical imaging, automatic cars/self-driving cars are becoming more popular these days. With the high-quality datasets of training visual data, the application of these technologies will be better than ever. You can find the sources here:
8. Visual Genome: A large and detailed dataset and knowledge base with captioning of over 100.000 images.
9. Google’s Open Images: A collection of over 9 million varied images with rich annotations. It contains image-level label annotations, object bounding boxes, object segmentation, and visual relationships across 6000 categories. This large image database is a great source of data for any data science project.
10. Youtube-8M: A vast dataset of millions of YouTube video IDs with high-quality machine-generated annotations of more than 3,800 visual entities. This dataset comes with pre-computed audio-visual features from billions of frames and audio segments.
Finding the suitable datasets for machine learning / AI is never easy. Besides the 4 categories mentioned above, the datasets can be Natural Language Processing Datasets, Audio Speech and Music Datasets for Machine Learning Projects, Data Visualization Datasets. You can check out other free source of datasets for machine learning with V7’s 65+ Best Free Datasets for Machine Learning.
However, the downside is that those open sources are not credible enough, so if your team accidentally gathers wrong data, your ML project will be affected badly, which reduces the level of accuracy for end-users. Also, collecting the data from unknown sources will cost you a great deal of time as it requires a lot of physical and manual labor.
So, the optimal strategy to get high-quality data for the task of labelling is to outsource to a professional vendor who has profound experience and knowledge providing data collection service to AI-based projects.
For your information, Lotus Quality Assurance is an expert at both data collection and annotation services. The datasets that Lotus Quality Assurance collects, including but not limited to images from reliable sources on the Internet, videos and sound captured and recorded with specific scenes, are provided with best quality and accuracy.
If you have any difficulties in data collecting or data annotation for your projects, feel free to reach out to us!
“We enjoy working with LQA because of the high quality of their work and their flexibility in accommodating any new task. In the past year, we had a variety of different projects, from simple bounding box annotations to complex pixel-wise segmentation, and every time the team was able to perform the task according to the specification and within the agreed time frame. We are very impressed with the amount of effort the team put into understanding of precise requirements and making sure there are no grey areas in the task before starting the work. The work processes seem very smooth and well organised, making the interactions easy and predictable. So far LQA have been one of our best experiences when working with external annotation teams.” – Daedalean
“Daedalean (www.daedalean.ai) was founded in 2016 with an aim to specify, build, test and certify a fully autonomous sensor and autopilot system that can reliably and completely replace the human pilot. Currently the company is working with EASA on an Innovation Partnership Contract to develop concepts of design assurance for neural networks.”
If you have any difficulties in data collecting or data annotation for your projects, feel free to reach out to us!
Data Annotation is the process of labelling the training data sets, which can be images, videos or audios. Needless to say, AI Annotation is of paramount importance to Machine Learning (ML), as ML algorithms need (quality) annotated data to process.
In our AI training projects, we use different types of annotation. Choosing what type(s) to use mainly depends on what kind of data and annotation tools you are working on.
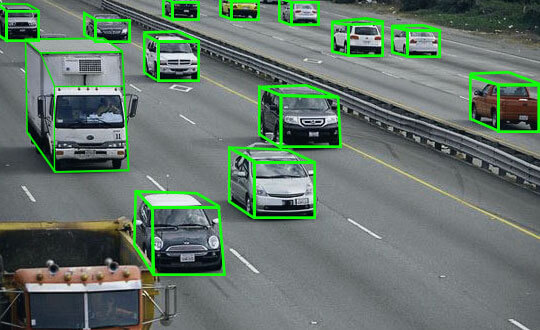
Bounding Box: As you can guess, the target object will be framed by a rectangular box. The data labelled by using bounding boxes are used in various industries, and most used in automotive vehicle, security and e-Commerce industries.
Polygon: When it comes to irregular shapes like human bodies, logos or street signs, to have more precise outcome, Polygons should be your choice. The boundaries drawn around the objects can give an exact idea about the shape and size, which can help the machine make better predictions.
Polyline: Polylines usually serve as a solution to reduce the weakness of bounding boxes, which usually contain unnecessary space. It is mainly used to annotate lanes on road images.
3D Cuboids: The 3D Cuboids are utilized to measure the volume of objects which can be vehicles, buildings or furniture.
Segmentation: Segmentation is similar to polygons but more complicated. While polygons just choose some objects of interest, with segmentation, layers of alike objects are labeled until every pixel of the picture is done, which leads to better results of detection.
Landmark: Landmark annotation comes in handy for facial and emotional recognition, human pose estimation and body detection. The applications using data labeled by landmark can indicate the density of the target object within a specific scene.
If you have any difficulties in data collecting or data annotation for your projects, feel free to reach out to us!
To provide the best experiences, we use technologies like cookies to store and/or access device information. Consenting to these technologies will allow us to process data such as browsing behavior or unique IDs on this site. Not consenting or withdrawing consent, may adversely affect certain features and functions.
Functional
Always active
The technical storage or access is strictly necessary for the legitimate purpose of enabling the use of a specific service explicitly requested by the subscriber or user, or for the sole purpose of carrying out the transmission of a communication over an electronic communications network.
Preferences
The technical storage or access is necessary for the legitimate purpose of storing preferences that are not requested by the subscriber or user.
Statistics
The technical storage or access that is used exclusively for statistical purposes.The technical storage or access that is used exclusively for anonymous statistical purposes. Without a subpoena, voluntary compliance on the part of your Internet Service Provider, or additional records from a third party, information stored or retrieved for this purpose alone cannot usually be used to identify you.
Marketing
The technical storage or access is required to create user profiles to send advertising, or to track the user on a website or across several websites for similar marketing purposes.